返回顶部
垃圾回收器设计
摘要
CPython 使用的主要垃圾回收算法是引用计数。基本思想是 CPython 统计有多少不同的地方引用了一个对象。这样的地方可以是另一个对象,或者一个全局(或静态)C 变量,或者某个 C 函数中的局部变量。当一个对象的引用计数变为零时,该对象将被释放。如果它包含对其他对象的引用,则这些对象的引用计数将递减。这些其他对象也可能被释放,如果这种递减使它们的引用计数变为零,依此类推。可以使用 >>> x = object ()
>>> sys . getrefcount ( x )
2
>>> y = x
>>> sys . getrefcount ( x )
3
>>> del y
>>> sys . getrefcount ( x )
2
引用计数方案的主要问题在于它无法处理引用循环。例如,考虑以下代码
>>> container = []
>>> container . append ( container )
>>> sys . getrefcount ( container )
3
>>> del container
在此示例中,container
从 3.13 版本开始,CPython 包含两个 GC 实现
这两个实现都使用相同的基本算法,但在不同的数据结构上操作。 GC 实现之间的差异
内存布局和对象结构
垃圾收集器需要 Python 对象中的附加字段来支持垃圾收集。这些额外字段在默认构建和自由线程构建中是不同的。
默认构建的 GC
通常,支持常规 Python 对象的 C 结构如下所示
为了支持垃圾收集器,对象的内存布局已更改,以便在正常布局之前 容纳额外信息
通过这种方式,对象可以被视为一个正常的 Python 对象,当需要与 GC 关联的额外信息时,可以通过从原始对象简单类型转换来访问前面的字段:((PyGC_Head *)(the_object)-1)
如 优化:重用字段以节省内存 部分稍后所解释的,这两个额外字段通常用于保存垃圾收集器跟踪的所有对象的双向链表(这些列表是 GC 代,更多内容请参见 优化:代 部分),但当不需要完整的双向链表结构作为内存优化时,它们也会被重用以实现其他目的。
使用双向链表,因为它们有效地支持最频繁需要的操作。通常,GC 跟踪的所有对象的集合被划分为不相交的集合,每个集合都在自己的双向链表中。在集合之间,对象被划分为“代”,反映了它们在收集尝试中幸存下来的频率。在收集期间,正在收集的代进一步划分为例如可达和不可达对象的集合。双向链表支持将对象从一个分区移动到另一个分区,添加新对象,完全删除对象(GC 跟踪的对象在 GC 根本不运行时最常被引用计数系统回收!),以及合并分区,所有这些都只需要少量恒定的指针更新。小心的话,它们还支持在向分区添加和从中删除对象时对其进行迭代,这在 GC 运行时经常需要。
自由线程构建的 GC
在自由线程构建中,Python 对象包含一个 1 字节字段 ob_gc_bits
请注意,并非所有字段都是可扩展的。 pad ob_mutex ob_gc_bits ob_ref_local ob_tid ob_ref_shared ob_type
垃圾收集器还会在收集期间暂时重新利用 ob_tid ob_ref_local
C API
提供特定的 API 来分配、释放、初始化、跟踪和取消跟踪具有 GC 支持的对象。这些 API 可以 垃圾收集器 C API 文档 中找到。
除了此对象结构外,支持垃圾回收的对象的类型对象必须在其 tp_flags Py_TPFLAGS_HAVE_GC tp_traverse tp_clear
识别引用循环
CPython 用于检测那些引用循环的算法在 gc 仅专注于 清理容器对象(即可以包含对一个或多个对象的引用的对象)。这些对象可以是数组、字典、列表、自定义类实例、扩展模块中的类等。人们可能会认为循环并不常见,但事实是解释器所需的许多内部引用到处都会创建循环。一些值得注意的示例
异常包含跟踪对象,其中包含包含异常本身的帧列表。
模块级函数引用模块的字典(需要它来解析全局变量),而该字典又包含模块级函数的条目。
实例引用它们的类,而类本身引用其模块,并且模块包含对其中所有内容(以及可能的其他模块)的引用,这可能会导致返回到原始实例。
在表示诸如图形之类的数据结构时,它们通常具有指向自身的内部链接。
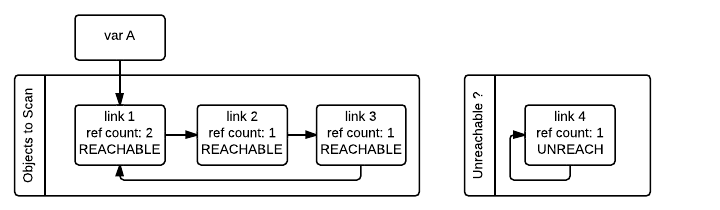
为了在这些对象变得不可达后正确处置它们,需要首先识别它们。为了了解算法的工作原理,让我们以一个循环链表为例,该链表有一个由变量 A
>>> import gc
>>> class Link :
... def __init__ ( self , next_link = None ):
... self . next_link = next_link
>>> link_3 = Link ()
>>> link_2 = Link ( link_3 )
>>> link_1 = Link ( link_2 )
>>> link_3 . next_link = link_1
>>> A = link_1
>>> del link_1 , link_2 , link_3
>>> link_4 = Link ()
>>> link_4 . next_link = link_4
>>> del link_4
# Collect the unreachable Link object (and its .__dict__ dict).
>>> gc . collect ()
2
GC 从一组它想要扫描的候选对象开始。在默认构建中,这些“要扫描的对象”可能是所有容器对象或更小的子集(或“代”)。在自由线程构建中,收集器始终操作扫描所有容器对象。
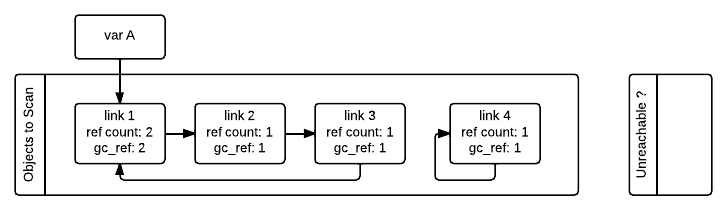
目标是识别所有不可达的对象。收集器通过识别可达对象来执行此操作;其余对象必须不可达。第一步是识别所有直接 从候选对象集外部可达的“要扫描”对象。这些对象的引用计数大于候选集内传入引用的数量。
每个支持垃圾回收的对象都将具有一个额外的引用计数字段,该字段在算法开始时初始化为该对象的引用计数(图中的 gc_ref
然后,GC 遍历第一个列表中的所有容器,并将容器引用的任何其他对象的 gc_ref tp_traverse gc_ref > 0
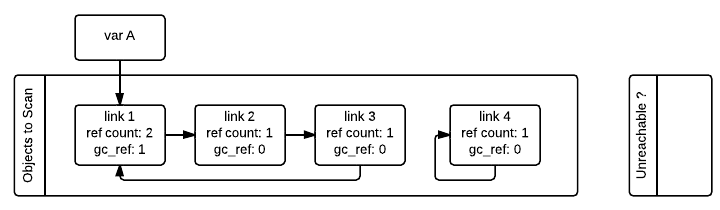
请注意,具有 gc_ref == 0 gc_ref > 0 link_2 gc_ref == 0 link_1 tp_traverse gc_ref == 0 link_3 link_4 link_1 link_2
然后,GC 扫描下一个 link_1 gc_ref == 1
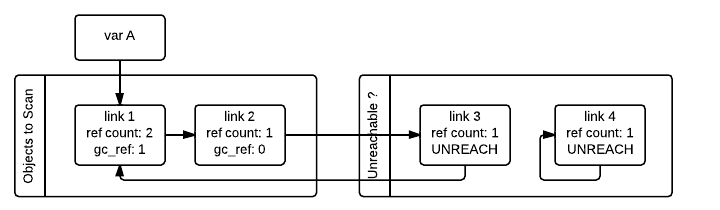
当 GC 遇到一个可访问的对象(gc_ref > 0 tp_traverse gc_ref link_2 link_3 link_1 link_1 link_3 gc_ref PREV_MASK_COLLECTING
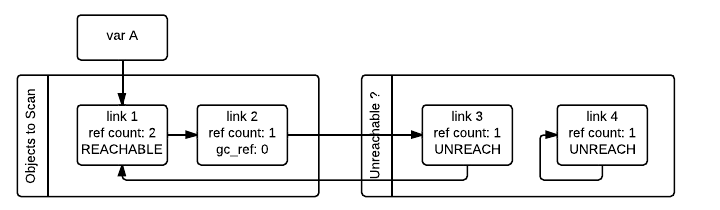
请注意,一个被标记为“暂时不可访问”并且后来被移回可访问列表的对象将再次被垃圾收集器访问,因为现在该对象拥有的所有引用也需要被处理。此过程实际上是对对象图的广度优先搜索。一旦扫描所有对象,GC 就知道暂时不可访问列表中的所有容器对象实际上是不可访问的,因此可以进行垃圾回收。
实际上,重要的是要注意,所有这些都不需要递归,并且也不需要以任何其他方式需要与对象数量、指针数量或指针链长度成正比的额外内存。除了内部 C 需求的 O(1)
为什么移动不可访问的对象更好
在大多数对象通常可访问的前提下,移动不可访问的对象听起来很合乎逻辑,直到你思考一下:它之所以值得,实际上并不明显。
假设我们按顺序创建对象 A、B、C。它们按相同的顺序出现在年轻代中。如果 B 指向 A,C 指向 B,并且 C 可从外部访问,那么在算法的第一步运行后调整后的引用计数将分别为 0、0 和 1,因为从外部可访问的唯一对象是 C。
当算法的下一步找到 A 时,A 被移动到不可访问列表中。当第一次遇到 B 时,B 也是如此。然后遍历 C,B 被移动回 可访问列表。最终遍历 B,然后 A 被移回可访问列表。
因此,可访问对象 B 和 A 并没有完全不动,而是各移动了两次。为什么这是一个胜利?一个直接的算法来移动可访问的对象只会移动 A、B 和 C 各一次。关键在于,这种移动将对象按顺序排列为 C、B、A - 它与原始顺序相反。在所有后续 扫描中,它们都不会移动。由于大多数对象不在循环中,因此这可以在无限数量的后续收集中节省无限数量的移动。唯一可能成本更高的时间是第一次扫描链时。
销毁不可访问的对象
一旦 GC 知道不可访问对象列表,一个非常精细的过程就会开始,目的是完全销毁这些对象。大致上,该过程按顺序执行以下步骤
处理并清除弱引用(如果有)。指向不可达对象的弱引用被设置为 None
如果对象具有旧式析构函数(tp_del gc.garbage
调用析构函数(tp_finalize
处理复活的对象。如果某些对象已复活,则 GC 会再次运行循环检测算法,找到仍然不可达的对象的新子集,并继续处理这些对象。
调用每个对象的 tp_clear
优化:代
为了限制每次垃圾回收所花费的时间,默认构建的 GC 实现使用了一种流行的优化:代。此概念背后的主要思想是假设大多数对象的生命周期非常短,因此可以在创建后立即收集它们。事实证明,这与许多 Python 程序的实际情况非常接近,因为许多临时对象会被创建并很快销毁。
为了利用这一事实,所有容器对象都被隔离到三个空间/代中。每个新对象都从第一代(第 0 代)开始。仅对特定代的对象执行前面的算法,如果一个对象在其代的收集中存活下来,它将被移到下一代(第 1 代),在那里它将被调查以进行收集的频率较低。如果同一对象在此新代(第 1 代)中存活了另一轮 GC,它将被移到最后一代(第 2 代),在那里它将被调查的频率最低。
自由线程构建的 GC 实现不使用多代。每个收集都在整个堆上操作。
为了决定何时运行,收集器会跟踪自上次收集以来对象分配和释放的数量。当分配数量减去释放数量超过 threshold_0 threshold_1 收集最旧的代 gc.get_threshold()
>>> import gc
>>> gc . get_threshold ()
(700, 10, 10)
可以使用 gc.get_objects(generation=NUM) gc.collect(generation=NUM)
>>> import gc
>>> class MyObj :
... pass
...
# Move everything to the last generation so it's easier to inspect
# the younger generations.
>>> gc . collect ()
0
# Create a reference cycle.
>>> x = MyObj ()
>>> x . self = x
# Initially the object is in the youngest generation.
>>> gc . get_objects ( generation = 0 )
[..., <__main__.MyObj object at 0x7fbcc12a3400>, ...]
# After a collection of the youngest generation the object
# moves to the next generation.
>>> gc . collect ( generation = 0 )
0
>>> gc . get_objects ( generation = 0 )
[]
>>> gc . get_objects ( generation = 1 )
[..., <__main__.MyObj object at 0x7fbcc12a3400>, ...]
收集最旧的代
除了各种可配置阈值之外,GC 仅在比率 long_lived_pending / long_lived_total
优化:重用字段以节省内存
为了节省内存,每个支持 GC 的对象中的两个链表指针被重新用于多个目的。这是一个常见的优化,称为“胖指针”或“标记指针”:携带附加数据、将数据“折叠”到指针中的指针,这意味着将数据存储在表示地址的数据中,利用内存寻址的某些属性。这是可能的,因为大多数架构将某些类型的数据对齐到数据的尺寸,通常是字或其倍数。这种差异导致指针的最低有效位没有使用,这些位可用于标记或保留其他信息——最常见的是作为位字段(每个位是一个单独的标记)——只要使用指针的代码在访问内存之前屏蔽掉这些位即可。例如,在 32 位架构(对于地址和字大小)上,一个字是 32 位 = 4 字节,因此字对齐的地址始终是 4 的倍数,因此以 00 000
CPython GC 使用两个胖指针,它们对应于 内存布局和对象结构 部分中讨论的 PyGC_Head
警告
由于存在额外信息,“标记”或“胖”指针不能直接解除引用,并且在获取真实内存地址之前必须剥离额外信息。直接操作链表的函数需要特别小心,因为这些函数通常假设列表中的指针处于一致状态。
_gc_prev PREV_MASK_COLLECTING _PyGC_PREV_MASK_FINALIZED _PyGC_PREV_MASK_FINALIZED _gc_prev gc_ref _gc_prev
_gc_next NEXT_MASK_UNREACHABLE NEXT_MASK_UNREACHABLE
优化:延迟跟踪容器
某些类型的容器不能参与引用循环,因此不需要垃圾收集器跟踪它们。取消对这些对象的跟踪可降低垃圾收集的成本。但是,确定哪些对象可以取消跟踪并不是免费的,并且必须权衡成本和垃圾收集的好处。取消跟踪容器时有两种可能的策略
在创建容器时。
当垃圾收集器检查容器时。
一般来说,不会跟踪原子类型的实例,而会跟踪非原子类型(容器、用户定义的对象…)的实例。但是,为了抑制简单实例的垃圾收集器占用空间,可以存在一些特定于类型的优化。受益于延迟跟踪的一些本机类型的示例
仅包含不可变对象(整数、字符串等,以及递归地包含不可变对象的元组)的元组不需要被跟踪。解释器会创建大量元组,其中许多元组在垃圾回收之前不会存在。因此,在创建时取消跟踪合格元组是不值得的。相反,在创建时跟踪除空元组之外的所有元组。在垃圾回收过程中,将确定是否可以取消跟踪任何幸存的元组。如果元组的所有内容都尚未被跟踪,则可以取消跟踪该元组。在所有垃圾回收周期中都会检查元组以取消跟踪。取消跟踪元组可能需要多个周期。
仅包含不可变对象的字典也不需要被跟踪。在创建时取消跟踪字典。如果将跟踪的项目插入到字典中(作为键或值),则该字典将被跟踪。在完全垃圾回收(所有代)期间,收集器将取消跟踪内容未被跟踪的任何字典。
垃圾回收器模块提供 Python 函数 is_tracked(obj)
>>> gc . is_tracked ( 0 )
False
>>> gc . is_tracked ( "a" )
False
>>> gc . is_tracked ([])
True
>>> gc . is_tracked ({})
False
>>> gc . is_tracked ({ "a" : 1 })
False
>>> gc . is_tracked ({ "a" : []})
True
GC 实现之间的差异
本节总结了默认构建中的 GC 实现和自由线程构建中的实现之间的差异。
默认构建实现广泛使用 PyGC_Head
默认构建实现使用 PyGC_Head
默认构建实现使用 PyGC_Head ob_tid
默认构建实现将标志存储在 PyGC_Head _gc_prev ob_gc_bits
默认构建实现依赖于 全局解释器锁
默认构建实现是代收集器。自由线程构建是非代收集器;每次收集都会扫描整个堆。
文档历史记录
Pablo Galindo Salgado - 原作者